DB | SQL 기초 연습 (1)에 이어 작성한다.
Implicit INNER JOIN
해당 포스팅 작성 시점은 아직 명시적 JOIN을 공부하기 전이라 WHERE 절에 조건을 작성하는 Implicit(묵시적) INNER JOIN으로 연습한다.
- 고객과 고객의 주문
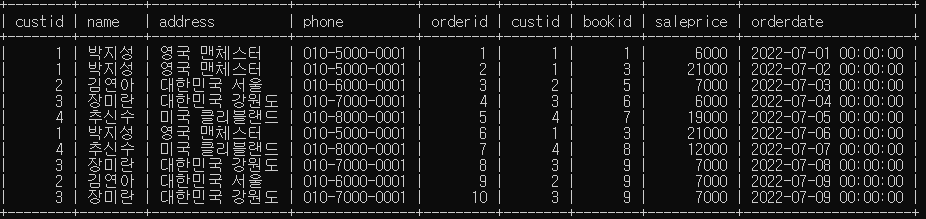
SELECT * FROM customer, orders
WHERE customer.custid = orders.custid;- 고객과 고객의 주문을 고객 번호로 정렬
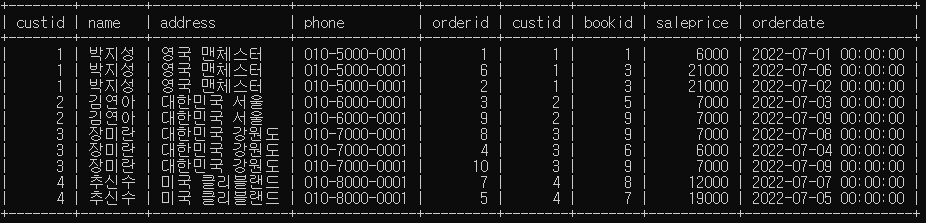
SELECT * FROM customer, orders
WHERE customer.custid = orders.custid
ORDER BY customer.custid;- 모든 주문에 대해 고객의 이름, 구매 금액
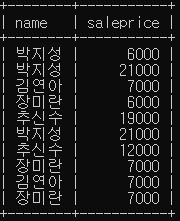
SELECT name, saleprice
FROM customer, orders
WHERE customer.custid = orders.custid;- 고객별 모든 구매 금액 합계를 구하고 고객 이름으로 정렬
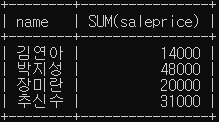
SELECT name, SUM(saleprice)
FROM customer, orders
WHERE customer.custid = orders.custid
GROUP BY name
ORDER BY name;- 고객의 이름, 구매 도서 제목

SELECT name, title
FROM customer, book, orders
WHERE customer.custid = orders.custid
AND book.bookid = orders.bookid;- 10,000원 이상 책을 구매한 고객의 이름과 구매 도서 재목

SELECT name, title
FROM customer, book, orders
WHERE customer.custid = orders.custid
AND book.bookid = orders.bookid
AND saleprice >= 10000;- 모든 고객 중 주문이 하나라도 있는 고객의 이름

SELECT name
FROM customer
WHERE custid IN (SELECT custid FROM orders);- 출판사 '대한미디어'의 도서를 구매한 고객의 이름

SELECT name
FROM customer
WHERE custid IN (SELECT custid
FROM orders
WHERE bookid IN (SELECT bookid
FROM book
WHERE publisher='대한미디어')
);위 SQL문을 이해하기 위해서는 마지막 SELECT부터 읽으며 해석해야 한다.
출판사 '대한미디어'의 도서 bookid를 구한다.
SELECT bookid FROM book WHERE publisher='대한미디어'위에서 구한 bookid에 해당하는 도서를 구매한 고객의 custid를 구한다.
SELECT custid FROM orders위에서 구한 custid에 해당하는 고객의 이름을 구한다.
SELECT name FROM customer
- 도서를 구매하지 않은 고객의 이름
SELECT name
FROM customer
WHERE custid NOT IN (SELECT custid
FROM orders);EXISTS
EXISTS는 IN과 같이 WHERE 뒤에 오며,
작성한 서브 쿼리에서 데이터가 존재하면 TRUE 반환 후 조회, 존재하지 않으면 FALSE를 반환한다.
- 주문이 있는 고객의 이름과 주소

SELECT name, address
FROM customer cust -- cust : customer table alias 지정
WHERE EXISTS (SELECT *
FROM orders ord
WHERE cust.custid = ord.custid);IN VS EXISTS
IN, EXISTS를 사용하면 동일한 결과를 얻을 수 있다.
그러나 큰 차이점이 존재한다.
EXISTS : 조건에 해당하는 row가 존재하는지 확인, 하나라도 찾으면 검색을 멈춘다. SELECT 절을 평가하지 않아 IN에 비해 성능 좋다.
IN : 조건에 해당하는 row의 column을 비교하여 확인. SELECT 절에서 조회한 column 값으로 비교해 EXISTS에 비해 성능 떨어진다.
서브 쿼리에서 조회되는 데이터가 많아지면 EXISTS 연산자를 사용하는 것이 좋다.
처리 순서
IN : 서브 쿼리 -> 메인 쿼리 / 서브 쿼리의 결과값을 메인 쿼리에 대입, 조건 비교 후 출력 / 서브 쿼리에서 메인 쿼리의 정보를 가져올 수 없기 때문에 조건을 각각 설정
EXISTS : 메인 쿼리 -> 서브 쿼리 / 메인 쿼리의 결과값을 서브 쿼리에 대입, 조건 비교 후 출력 / 서브 쿼리에서 메인 쿼리의 정보를 가져와 모든 조건을 한번에 설정
출판사 '대한미디어'의 도서를 구매한 고객의 이름의 예를 보면 IN의 처리 순서를 더 잘 이해할 수 있다.
IN, EXISTS의 차이와 같이 공부가 더 필요한 또 다른 이론적인 부분들은 추후에 개별 포스팅을 통해 자세히 다룰 예정이다.
'DB' 카테고리의 다른 글
| DB | 데이터 모델링, 개체-관계 모델(E-R Model) (0) | 2023.02.26 |
|---|---|
| DB | 데이터베이스 시스템 정의와 구성 요소, 3단계 데이터베이스 구조 (2) | 2023.01.02 |
| DB | SQL 기초 연습 (1) (0) | 2022.08.17 |
| DB | MySQL 정리 (0) | 2022.08.15 |
| DB | DATABASE1 정리 (0) | 2022.08.15 |