DB
정보 관리 도구인 파일은 사용하기 쉽고 어디에나 있으면서 전송하기 편리해 지금도 사용하고 있다. DB도 결국 데이터를 파일에 저장한다.
정보의 양이 증가하고 다양해지면서 파일만으로는 정보를 효과적으로 입력, 저장, 출력하는 것이 어려워졌다. 데이터를 잘 정리정돈해서 필요할 때 꺼내서 쓰고 싶은 욕구가 생겼고 누구나 쉽게 데이터를 정리정돈할 수 있는 전문적인 소프트웨어 DB가 등장했다.
관계형 DB는 데이터를 표의 형태로 정리정돈하기가 가능하며 정렬, 검색 작업을 빠르고 안전하게 할 수 있다.
MySQL, Oracle 등은 관계형 DB라는 토대 위에서 만들어진 기술이기 때문에 하나만 배워도 다른 것을 배우기가 쉽다. 무료이고 오픈소스이며 관계형 DB의 주요 기능을 갖추고 있는 MySQL을 학습한다.
MySQL
스프레스시트와 마찬가지로 데이터를 표의 형태로 표현해준다. 기능이 서로 비슷하다.
가장 중요한 차이점은 DB는 코딩을 통해서, 컴퓨터 언어를 통해서 제어가 가능하다는 것이다.
관계형 DB는 SQL이라는 언어를 이용해 데이터를 제어한다. DB의 데이터를 웹, 앱을 통해 사람들에게 공유할 수도 있고 분석할 수도 있다.
웹과 DB 기술을 결합하면 웹에 접속해서 데이터를 볼 수 있게 할 수 있다. 직접 DB를 제어하지 않아도 사용자들이 웹페이지에 글을 쓰면 DB에 저장된다.
MySQL 설치
웹서버 운영 맛보기 포스팅에서 설치한 Bitnami를 같은 방법으로 설치하면 MariaDB가 알아서 같이 설치된다. MySQL과 동일한 소스코드를 기반으로 하기 때문에 MySQL 대신 사용해도 된다.
cmd 창에서 mariadb의 bin 폴더로 이동한다.
cd C:\Bitnami\wampstack-7.4.21-0\mariadb\bin이동 후 mysql을 실행한다. 설치된 건 MariaDB지만 아래 명령어를 써도 괜찮다. 아래 명령어를 입력하고 설치할 때 설정한 비밀번호를 입력하면 정상적으로 실행된다.
mysql -uroot -pMySQL의 3가지 구성요소

데이터를 기록하는 최종적인 곳은 table(표)이다.
웹사이트를 운영하고 데이터를 DB에 저장하면 게시물을 저장하는 표, 댓글을 저장하는 표, 회원정보를 저장하는 표 등 table이 많아진다. 정리정돈의 필요성이 생긴다.
서로 연관된 테이블을 그룹핑해서 연관된 것과 연관되지 않은 테이블을 분리하는데 사용하는 파일의 폴더들이 DB이다.
DB == Schema(스키마) : 표들을 그룹핑할 때 사용하는 일종의 폴더이다.
스키마가 많아지면 데이터베이스 서버에 저장한다. MySQL이 데이터베이스 서버 프로그램을 설치한 것이고 그 프로그램을 가지고 데이터 관련 작업을 수행하는 것이다.
얻을 수 있는 효용
보안이다. DB 자체적인 보안 체계로 안전하게 데이터 보관이 가능하고 권한 기능이 있어서 여러 사람을 등록할 수 있다. 읽기, 쓰기, 수정, 삭제 권한을 일부만 주거나 차등적으로 부여할 수 있다.
MySQL을 설치하고 접속하기 위해 입력했던 명령어인 -uroot는 root라는 사용자로 접속한다는 뜻이다. 기본 유저가 root이고 관리자이기 때문에 모든 권한이 열려있다.
실제로 root의 권한으로 DB를 직접 다루는 것은 위험하다. 중요한 프로그램이라면 별도의 사용자를 만들어서 평소에는 그 사용자로 작업을 하다가 중요한 작업을 할 때만 root로 접속하는 것을 권장한다.
비밀번호를 입력하고 MySQL 접속에 성공하는 것은 DB 서버 담장을 넘은 것이라고 할 수 있다.
스키마 생성, 삭제, 출력, 사용
스키마를 생성하기 위해 CREATE 명령어를 사용한다.
CREATE DATABASE practice; // practice라는 이름을 가지는 스키마 생성생성된 스키마를 삭제하기 위해 DROP 명령어를 사용한다.
DROP DATABASE practice; // practice 스키마를 삭제생성되어 있는 스키마 리스트를 출력하기 위해 SHOW 명령어를 사용한다.
SHOW DATABASES;
SHOW SCHEMAS;생성되어 있는 스키마 중 하나를 사용하기 위해 USE 명령어를 사용한다.
USE practice; // practice 스키마를 사용USE 명령어를 사용한 후부터 해당 스키마에 있는 테이블을 대상으로 앞으로의 명령을 실행한다.
명령어를 전부 외울 필요가 없다. 필요에 따라 검색을 통해서 알면 된다.
SQL
SQL은 컴퓨터 언어이다. Structured Query Language
표를 작성하는 것, 정리정돈은 구조화 되었다는 뜻 -> Structured
Query -> 무언가 요청한다.
SQL로 말하면 MySQL Server가 알아듣는다.
SQL은 관계형 DB 제품들이 공통적으로 DB 서버를 제어할 때 사용하는 언어로 표준화가 되어있다.
table 구조
table을 x축, y축으로 쪼갤 수 있다.
수평, row, record, 행 : 데이터 하나하나, 데이터 자체
수직, column, 열 : 데이터의 타입, 데이터의 구조
table 생성
USE practice 명령어를 통해 스키마를 선택하고 테이블을 생성한다.
테이블을 생성하기 위해서 CREATE TABLE 명령어를 사용한다.
CREATE TABLE topic(
id INT(11) NOT NULL AUTO_INCREMENT,
title VARCHAR(100) NOT NULL,
description TEXT NULL,
created DATETIME NOT NULL,
author VARCHAR(30) NULL,
profile VARCHAR(100) NULL,
PRIMARY KEY(id)
);NULL : 값이 없는 것을 허용.
NOT NULL : 값이 없는 것을 허용하지 않음.
AUTO_INCREMENT : 데이터를 추가할 때마다 알아서 1씩 증가한다.
PRIMARY KEY : 다른 항목과 중복되어 나타날 수 없는 단일값이며 NULL 불가, 고유한 값


INT(n)에서의 n은 인터넷 검색을 통해 자세히 알아봤다. zerofill 옵션과 함께 사용할 수 있는데 괄호 안 n만큼 빈칸을 0으로 채우라는 의미이다.
INT(3) zerofill로 생성한 column에 1을 삽입하면 실제로는 001이 삽입되어 있다.
Create, Read
다 중요하지만 가장 중요한 것은 Create, Read이다. 어떤 DB를 만나든 일단 Create, Read 방법이 무엇인지를 알아야 한다.
CREATE - INSERT, 삽입
데이터를 삽입한다. 데이터 삽입 전 테이블 구조를 보고 싶을 때 DESC 명령어를 사용한다.
DESC topic;테이블에 데이터를 삽입하기 위해 INSERT 명령어를 사용한다.
INSERT INTO topic (title, description, created, author, profile) VALUES('MySQL', 'MySQL is ...', NOW(), 'Usagi', 'developer');
INSERT INTO topic (title, description, created, author, profile) VALUES('ORACLE', 'ORACLE is ...', NOW(), 'Usagi', 'developer');
INSERT INTO topic (title, description, created, author, profile) VALUES('SQL Server', 'SQL Server is ...', NOW(), 'Rei', 'data administrator');
INSERT INTO topic (title, description, created, author, profile) VALUES('PostgreSQL', 'PostgreSQL is ...', NOW(), 'Ami', 'data scientist, developer');
INSERT INTO topic (title, description, created, author, profile) VALUES('MongoDB', 'MongoDB is ...', NOW(), 'Usagi', 'developer');id는 AUTO-INCREMENT이므로 입력하지 않아도 된다.
NOW() : 함수이며, 현재 시간이 자동으로 삽입된다.
데이터가 삽입된 것을 확인하기 위해 SELECT 명령어를 사용한다.
SELECT * FROM topic;
READ - SELECT, 조회
- 모든 데이터 조회
SELECT * FROM topic;- 특정 column만 조회
SELECT id, title, author FROM topic; // id, title, author 데이터만 출력
- 특정 데이터 가진 row만 조회
SELECT id, title, author FROM topic WHERE author='Usagi';
- id값 기준 정렬
SELECT id, title, author FROM topic WHERE author='Usagi' ORDER BY id DESC;
- 조회하는 row의 개수 제한
SELECT id, title, author FROM topic WHERE author='Usagi' ORDER BY id DESC LIMIT 2;
SELECT 명령어를 필요에 따라 잘 사용해야 한다.
UPDATE, 수정
데이터를 수정하기 위해 UPDATE 명령어를 사용한다.
UPDATE topic SET title='Oracle', description='Oracle is ...' WHERE id=2;WHERE가 빠지면 어떤 행에 해당하는 데이터를 수정하는지 알 수 없기 때문에 WHERE 명령어를 꼭 사용한다.

DELETE, 삭제
데이터를 삭제하기 위해 DELETE 명령어를 사용한다.
DELETE FROM topic WHERE id=5;WHERE가 빠지면 모든 행이 삭제되므로 꼭 작성해야 한다.

관계형 DB의 의미와 필요성
중복되는 데이터가 있다는 것은 개선할 여지가 있다는 뜻이다.
author에는 이름이 들어가는데 만약 동명이인에 profile까지 같다면 수정할 때 오랜 시간이 걸리게 되거나 문제가 생긴다.
따라서 테이블을 분리한다.
author 정보를 별도의 테이블로 뺀다.
author 테이블에는 id, name, profile column이 존재하고 기존의 topic 테이블에서 author, profile을 삭제하고 author_id column을 생성한다. author_id column에는 author 테이블의 id값을 참조해 삽입한다.
만약 author 정보에 수정사항이 생기면 author 테이블에서 한번만 수정하면 author 테이블을 참조하고 있는 topic 테이블의 행에서 데이터가 수정되었다라고 할 수 있다. 유지보수가 편해지고 동명이인 구분을 쉽게 할 수 있게 된다.
장점만 생기는 것 같지만 단점 역시 생긴다. 이를 trade-off라 한다.
기존의 방식에서는 topic 하나의 테이블에 모든 데이터가 드러나기 때문에 직관적이다. 하지만 테이블을 별도로 쪼개서 참조값만을 삽입해놓으면 데이터에 해당되는 별도의 표를 열어서 비교해야 한다.
이 단점을 해결하기 위해 MySQL의 JOIN이 등장한다.
데이터를 별도의 테이블로 보관하면서 중복을 발생시키지 않고 하나의 테이블로 합쳐진 결과를 볼 수 있다.
저장은 분산해서 조회할 땐 합쳐서
테이블 분리
RENAME TABLE topic TO topic_backup; // 기존의 topic 테이블 이름 변경
// author 테이블 생성
CREATE TABLE author (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(20) NOT NULL,
profile varchar(200) DEFAULT NULL,
PRIMARY KEY (id)
);
// author 테이블에 데이터 삽입
INSERT INTO author VALUES (1, 'Usagi', 'developer');
INSERT INTO author VALUES (2, 'Rei', 'database administrator');
INSERT INTO author VALUES (3, 'Ami', 'data scientist, developer');
// 새로운 topic 테이블 생성
CREATE TABLE topic (
id int(11) NOT NULL AUTO_INCREMENT,
title varchar(30) NOT NULL,
description text,
created datetime NOT NULL,
author_id int(11) DEFAULT NULL,
PRIMARY KEY (id)
);
// 새로운 topic 테이블에 데이터 삽입
INSERT INTO topic VALUES (1, 'MySQL', 'MySQL is...', '2021-10-20 13:45:11', 1);
INSERT INTO topic VALUES (2, 'Oracle', 'Oracle is ...', '2021-10-20 13:46:15', 1);
INSERT INTO topic VALUES (3, 'SQL Server', 'SQL Server is ...', '2021-10-20 13:49:09', 2);
INSERT INTO topic VALUES (4, 'PostgreSQL', 'PostgreSQL is ...', '2021-10-20 13:52:48', 3);
INSERT INTO topic VALUES (5, 'MongoDB', 'MongoDB is ...', '2021-10-20 13:56:02', 1);
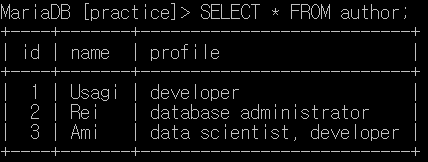
JOIN
topic 테이블의 모든 행을 출력하는데 author_id의 값과 같은 값을 가지고 있는 author 테이블의 행을 가져와서 topic 테이블에 붙여 출력하기 위해 JOIN 명령어를 사용한다.
SELECT * FROM topic LEFT JOIN author ON topic.author_id = author.id;
- author_id와 id를 제외하고 조회
SELECT topic.id, title, description, created, name, profile
FROM topic
LEFT JOIN author ON topic.author_id = author.id;topic 테이블과 author 테이블에 모두 id column이 있으므로 topic 테이블의 id는 조회하고 싶다면 topic.id를 입력해야 한다.

- AS, 실제 수정은 아니지만 조회할 때 topic의 id column을 topic_id로 바꾸는 방법
SELECT topic.id AS topic_id, title, description, created, name, profile
FROM topic
LEFT JOIN author ON topic.author_id = author.id;AS는 별칭을 지정하는 것이다.

어떤 테이블이라도 author 식별자인 id와 일치하는 식별자값을 포함하고 있다면 JOIN을 통해 얼마든지 관계를 맺을 수 있다.
인터넷과 DB의 관계
MySQL은 내부적으로 인터넷을 활용할 수 있도록 고안된 시스템이다.
인터넷은 정보를 요청하는 쪽과 응답하는 쪽으로 나누어지는데 쉽게 말하면 갑과 을에 해당하는 컴퓨터가 정보를 요청하고 응답하는 시스템이다.
MySQL을 설치하면 DB 클라이언트, DB 서버가 설치된다.
DB 서버는 직접 다룰 수 없고 어떤 형태로는 DB 클라이언트를 사용해야 한다.
지금까지 cmd 창에서 사용한 DB 클라이언트가 바로 MySQL Monitor이다.

MySQL을 설치하면 MySQL 서버에 접속할 수 있도록 기본적인 번들로 제공되는 클라이언트인 것이다. MySQL Monitor는 명령어를 통해서 DB 서버를 제어하는 프로그램이다.
MySQL Monitor가 CLI 기반이라면 GUI 기반인 MySQL Workbench가 존재한다. 엑셀을 다루듯이 DB를 다룰 수 있게 되는 것이다.
DB 서버에 데이터를 저장하고 전 세계에 있는 수많은 DB 클라이언트들이 DB 서버를 중심으로 테이터를 넣고 빼는 것이 가능하다.
웹, 앱과 값은 ui가 아니더라도 DB 클라이언트를 이용해 DB 서버를 통해 여러가지 정보를 주고 받고 관리하는 것이 가능한 것이다.
하고자 하는 일이 무엇인지에 따라 알맞은 클라이언트를 선택하는 것이 중요하다.
mysql -uroot -p -hlocalhost
MySQL에 접속하기 위해 지금까지 사용했던 명령어는 -hlocalhost가 생략된 것이다.
h는 host로 인터넷에 연결되어 있는 각각의 컴퓨터이고 만약 인터넷을 통해 다른 컴퓨터에 있는 MySQL 서버에 접속하려고 하면 -h"주소"를 적어주면 된다.
우리는 MySQL 클라이언트와 MySQL 서버가 같은 컴퓨터에 위치하고 있으므로 자신의 컴퓨터를 가리키는 약속된 특수한 도메인 localhost를 사용한 것이다.
MySQL Workbench
MySQL Workbench를 설치한다.
강의를 들으며 똑같은 방법으로 설치했으나 서버가 등록되지 않고 SSL 오류가 발생했다. 검색을 통해서 계속 해결하려고 했는데 해결하지 못했다가 낮은 버전으로 설치하니까 오류가 발생하지 않았다. SSL은 서버 인증서라고 하는데 최신 버전에서는 Use SSL 설정에 낮은 버전에는 존재하는 No, If available 설정값이 존재하지 않았다. 이 때문에 오류가 발생한 것 같다.
MySQL Workbench를 실행해

+를 눌러 connection을 진행한다.

설정한 비밀번호를 입력하면 접속할 수 있게 된다.
좌측 SCHEMAS를 보면 지금까지 생성했던 모든 스키마와 테이블을 확인할 수 있다.




Query 1 창에 명령을 쓰고 번개 버튼을 누르면 명령이 실행된다.
새로운 스키마와 테이블을 생성하고 데이터를 삽입해봤다. 아래 사진 속 버튼을 통해 쉽게 생성이 가능하다.




PK : primary key
NN : not null
AI : auto increment
GUI지만 결국 명령어로 전달되는 것이다. 버튼을 누르면 SQL 명령어를 생성해 서버에게 전달하는 방식이다. 결국 어떤 클라이언트를 사용하든 SQL을 MySQL 서버에 전송해 DB 서버를 제어하게 된다.
MySQL 서버를 사용하고 있는 모든 웹 애플리케이션, 앱, 데이터 분석 시스템들은 본질적으로 모두 MySQL 클라이언트인 셈이다.
마무리
SQL을 잘 이해하고 사용할 줄 알아야 DB를 더 잘 이용할 수 있게 된다.
Read에 해당하는 SELECT 명령어를 열심히 익혀야 한다.
색인 기능을 걸어두면 DB가 column의 데이터를 정리정돈 -> index 키워드
table 설계를 처음부터 잘 해야 한다. -> modeling
backup이 중요 -> 데이터를 복제 보관, 별도의 컴퓨터에 보관 -> mysqldump, binary log 키워드
내 컴퓨터를 DB 서버로 쓰지 않고 큰 회사들이 운영하고 있는 인프라 위에 있는 컴퓨터를 임대해 사용 -> 클라우드 -> AWS RDS, google cloud sql for mysql, azure database
DB 시스템을 일종의 부품으로 해서 여러 정보 시스템의 완제품이 만들어진다.
Python mysql api, PHP mysql api, Java mysql api -> 각 언어로 DB 시스템을 쉽게 핸들링 할 수 있다.
'DB' 카테고리의 다른 글
| DB | 데이터 모델링, 개체-관계 모델(E-R Model) (0) | 2023.02.26 |
|---|---|
| DB | 데이터베이스 시스템 정의와 구성 요소, 3단계 데이터베이스 구조 (2) | 2023.01.02 |
| DB | SQL 기초 연습 (2) (0) | 2022.08.26 |
| DB | SQL 기초 연습 (1) (0) | 2022.08.17 |
| DB | DATABASE1 정리 (0) | 2022.08.15 |